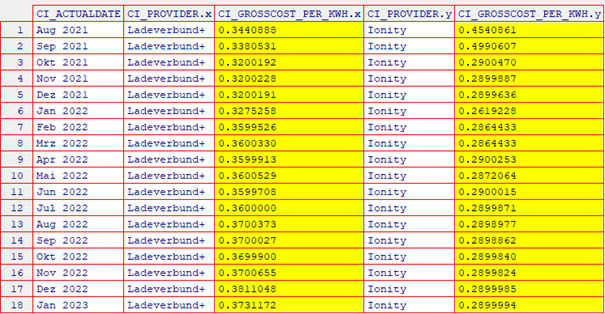
Sofort ist zu erkennen, dass das allgemeine Level des jeweiligen Preises beim Anbieter „Ladeverbund+“ höher liegt, als beim Anbieter „Ionity“.
Bei „Ionity“ ist der Preisniveau-Absturz vom Sept. 2021 auf Okt. 2021 zu erkennen, was auf eine Tarifanpassung zurückzuführen ist. Mit dem Tarif Ionity Premium haben wir einen festen Preis von 0,29 EUR pro kWh.
Analyse der Zeitreihe für den Anbieter „Ionity“
Mal angenommen, dass wir über die Existenz eines festen Tarifs nichts wissen...
Für diesen Anbieter ist die s.g. naive Vorhersage am plausibelsten, wenn man als Forecast für die nächste Zeitperiode einfach den Wert der letzten Zeitperiode nimmt.
Wenn man bedenkt, dass bei diesem Anbieter der durchschnittliche monatliche Bruttopreis pro Kilowattstunde seit Februar 2022 stets fast konstant bleibt (bitte s. Grafik und Tabelle oben), - wäre die naive Vorhersage die einzige rationale Wahl in dieser Situation gewesen.
Die s.g. naive Vorhersage ist übrigens auch die Vorhersage, die man hauptsächlich bei den Aktienkursen als Forecast anwendet.
In diesem Sinne ist die Vorhersage für den Anbieter „Ionity“ für die nächste Zeitperiode (Feb. 2023) nichts anderes als der tatsächlich beobachtete Wert für Jan. 2023, nämlich ca. 0,29 EUR pro kWh.
Analyse der Zeitreihe für den Anbieter „Ladeverbund+“
Bei diesem Anbieter ist es nicht alles so eindeutig wie bei „Ionity“.
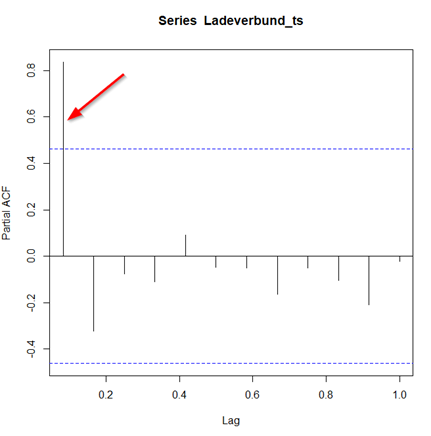
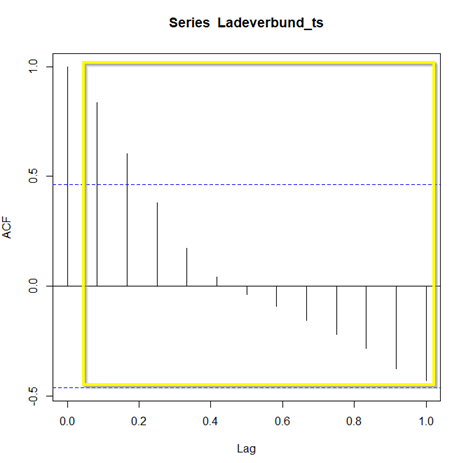
Zwar ist die Zeitreihe an sich auch flach und ohne bemerkenswerte Ereignisse, dennoch ist ein geringfügiger positiver Trend (langsame Preissteigerung) in dieser Zeitreihe zu erkennen.
Aus meiner Erfahrung würde ich auf Anhieb auf ein Random Walk (zufälliges Fluktuieren) tippen, allerdings habe ich bei dieser Zeitreihe den Verdacht, dass es sich hier um den s.g. Random Walk mit Drift handelt.
Ein Random Walk mit Drift wird als AR(1) (Autoregressive Process of order 1) Prozess bezeichnet, wo die jeweils nächste Beobachtung der kompletten jeweiligen vorigen Beobachtung entspricht (theta-Koeffizient ist gleich eins) plus etwas weißes Rauchen (random noise), und dazu noch eine arbiträre additive und - in diesem Fall - positive Konstante zu dieser Konstellation hinzugefügt.
Diese arbiträre additive und positive Konstante wäre in diesem Fall der s.g. langsame Drift der Preisentwicklung tendenziell zu einem höheren durchschnittlichen Niveau, und könnte womöglich eine andere, hier nicht vorhandene latente Variable an sich darstellen, etwa die Preissteigerung für die Rohstoffe der entsprechenden Energiegewinnung.
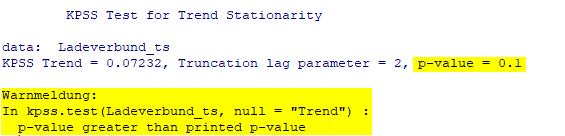
Diese Hypothese vom Random Walk mit Drift muss noch überprüft werden. Es kann durchaus sein, dass man hier nur mit einem einfachen Random Walk zu tun hat, so dass der langsame positive Trend nur zufällig anhand sporadischer Fluktuationen entstanden sei (etwa die Preisanpassung anhand des jeweiligen zufälligen täglichen Konsums) und nicht etwa durch die kontinuierliche absichtliche Preisanpassung in Abhängigkeit von einer externen latenten Variable (etwa steigende Rohstoffpreise oder z.B. evtl. eine kontinuierlich steigende Nachfrage).
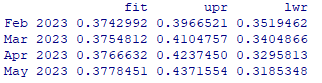
Um die Hypothese von Random Walk mit Drift für den Anbieter „Ladeverbund+“ zu überprüfen, haben wir das zweifache exponentielle Glätten (Holt‘s exponential smoothing) auf die Zeitreihe mit dem folgenden Ergebnis angewendet: