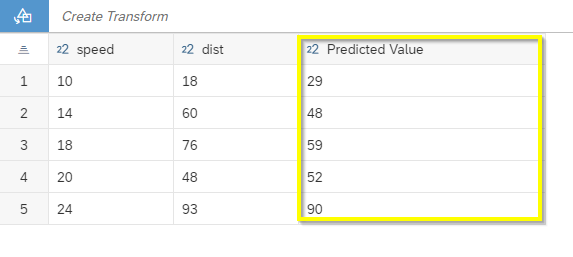
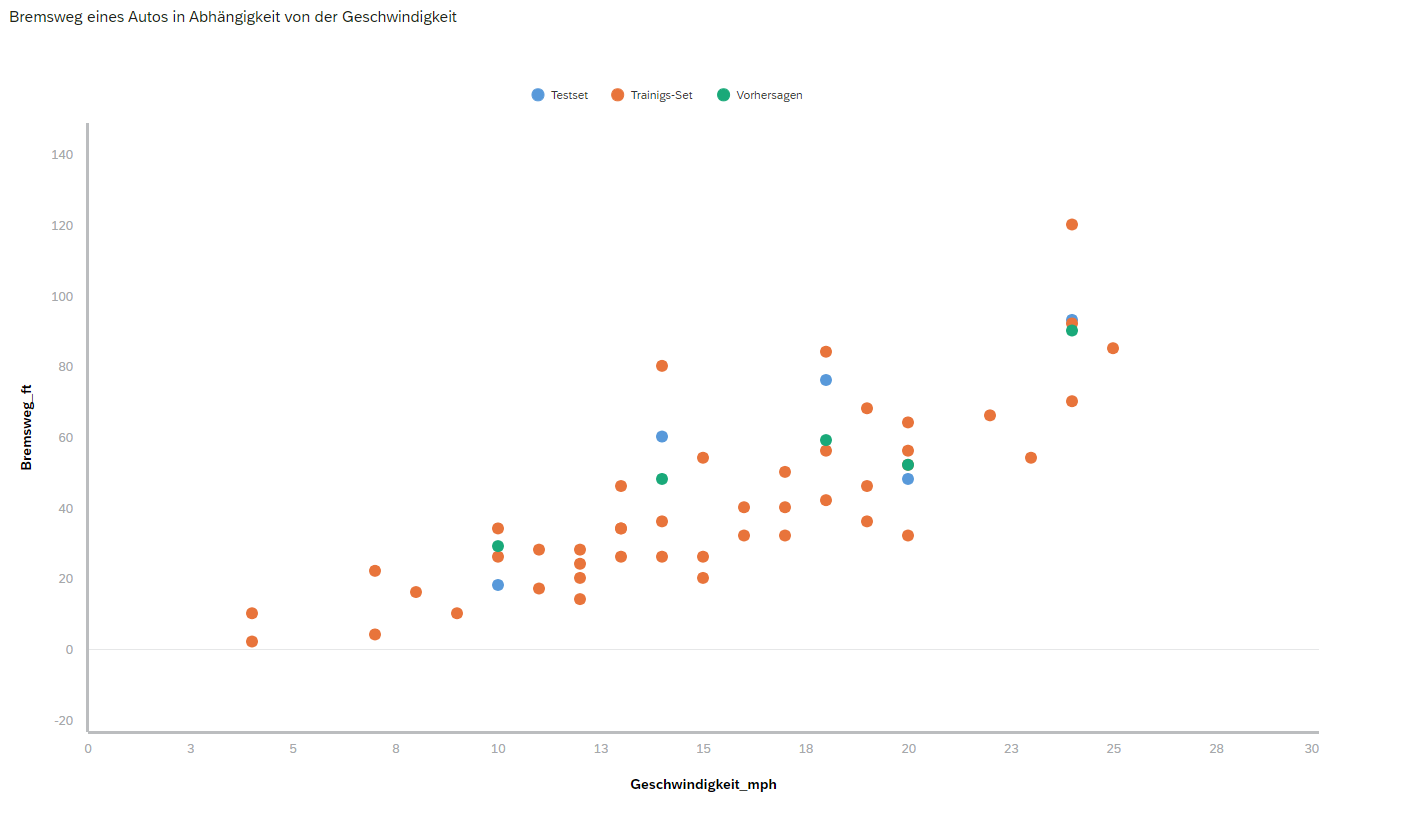
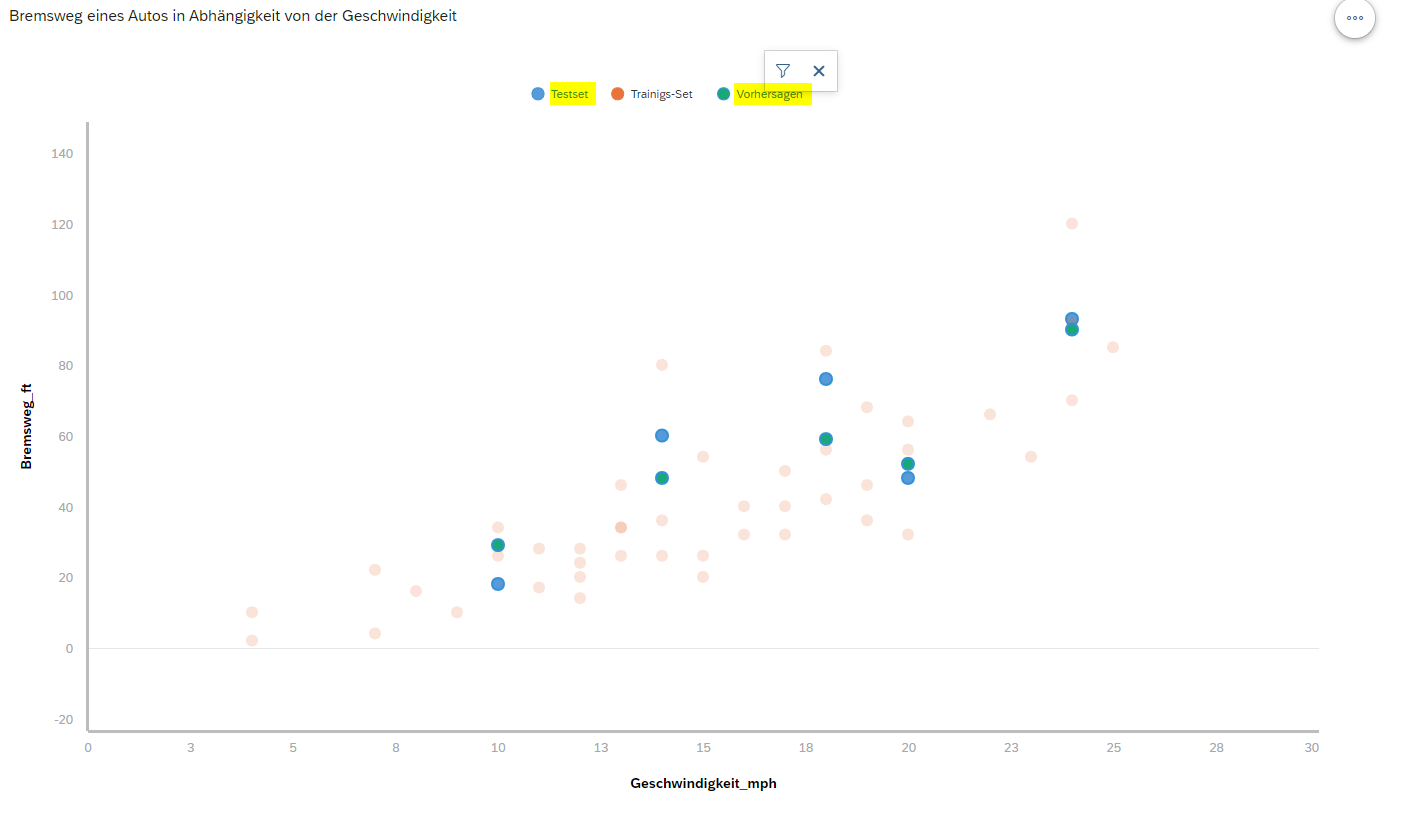
Die Error Metriken für diese Vorhersagen sehen folgendermaßen aus:
RMSE: 10.76104
MAE: 9.4
MAPE: 0.2300773
Man sieht, dass diese Werte eine Verbesserung an sich darstellen im Vergleich mit den Error Metriken, die wir oben in R mithilfe einfacher linearer Regression erzielt haben: MAPE von 0.27 in R vs. 0.23 in der SAC.
Das ist auch nicht verwunderlich, da der nicht-parametrische Gradient Boosting Regressionsbaum, der in SAC verwendet wird, nicht an einen linearen Zusammenhang in den Daten gebunden ist und daher viel flexibler und dementsprechend effizienter agieren kann.
Besonders ist es auffällig, wenn die Variabilität der Residuen um ihren Mittelwert (Null-Wert) hoch ist, - was bei diesem Datensatz tatsächlich der Fall ist.
In solchen Fällen wird ein nicht-parametrischer Ansatz (was in SAC benutzt wird) den parametrischen (linearen) Ansatz (fast) immer schlagen.
Selbst wenn die Heteroskedastizität für das lineare Modell eliminiert wurde, variieren die Residuen dennoch sehr stark um ihren Mittelwert (Varianz der Residuen ist zwar stationär geworden, dennoch ist die Streuung zu hoch) - was von einer Unvollständigkeit des gewählten Modells spricht - und dementsprechend kann das einfache lineare Modell diese hohe Streuung auch nicht kohärent erfassen.
Der nicht-parametrische Ansatz eines Regressionsbaums (SAC Modell) wäre hier tatsächlich die richtige Wahl gewesen.
Dennoch beträgt die Minderung beim durchschnittlichen prozentualen Fehler (MAPE) lediglich ca. 3,5 Prozentpunkte (vgl. oben mit MAPE für OLS in R), was nicht sonderlich nach einer signifikanten Verbesserung des Modells klänge.
Dieser Umstand bestätigt lediglich die These, dass man zusätzliche Merkmale in das Modell aufnehmen soll, um die Streuung der abhängigen Variable besser erfassen zu können, und erst danach ein statistisches Modell bilden.
Fazit
Die Regression ist ein sehr mächtiges Werkzeug und kann mittels sehr unterschiedlicher Techniken bewerkstelligt werden.
Die Statistik-Software R beherrscht alle existierenden Verfahren, von einem einfachen linearen Modell aus diesem Blogbeitrag, bis hin zu sehr komplexen Verfahren, die mithilfe vom stochastischen Gradientenabstieg die neuronalen Netze mit mehreren versteckten Schichten trainieren und die Regressions-Aufgaben lösen können.
Man ist in R sehr flexibel, wenn es um die Auswahl einer bestimmten Technik geht, denn alles kann auch in R nachgebaut werden.
In der SAC hat man im Gegensatz dazu, ausschließlich die Methode(n) verfügbar, die dort implementiert wurde(n). Man ist quasi an diese einzige vorkonfektionierte Lösung gebunden.
Dennoch sind in vielen Situationen die SAC Lösungen ausreichend gut genug, um die Predictive Analytics Szenarien zu verwirklichen.
In diesem Sinne: viel Spaß beim Modellieren!