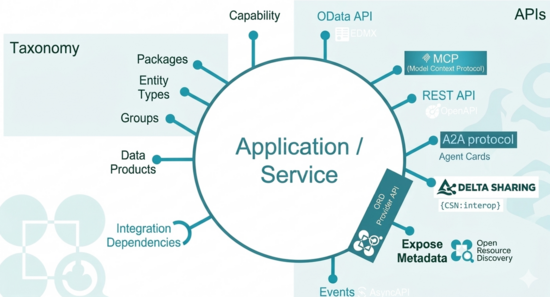
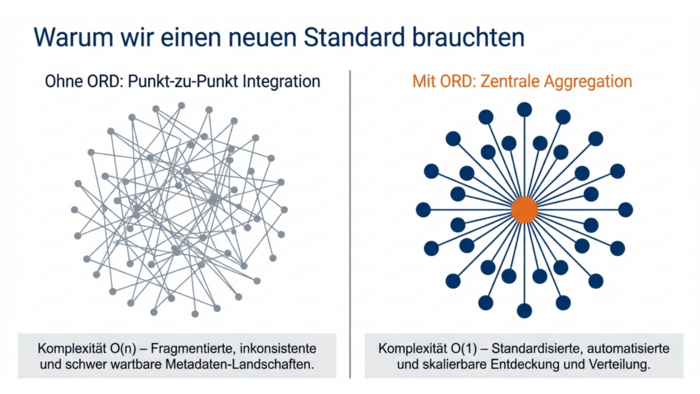
Open Resource Discovery (ORD) ist ein offener Standard, der ursprünglich von SAP entwickelt wurde und als „universelle Sprache“ für Anwendungen dient, damit diese sich selbst beschreiben können. Das Ziel von ORD ist es, das Problem von uneinheitlichen und verstreuten Metadaten zu lösen, das oft über verschiedene Systeme und Protokolle hinweg herrscht.
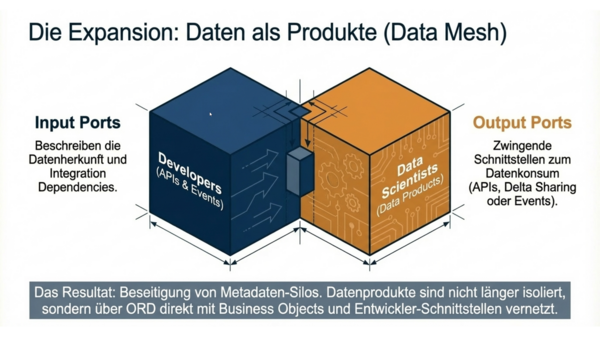
Das Besondere an ORD ist seine Vielseitigkeit: Es kann einerseits genutzt werden, um statische Dokumentationen (wie zum Beispiel für API-Kataloge) zu beschreiben. Andererseits kann es aber auch die ganz individuellen Konfigurationen und Erweiterungen widerspiegeln, die in einer spezifischen Systemumgebung zur Laufzeit aktiv sind. So wissen Entwickler und Maschinen immer ganz genau, wie sie ein System aktuell nutzen können.