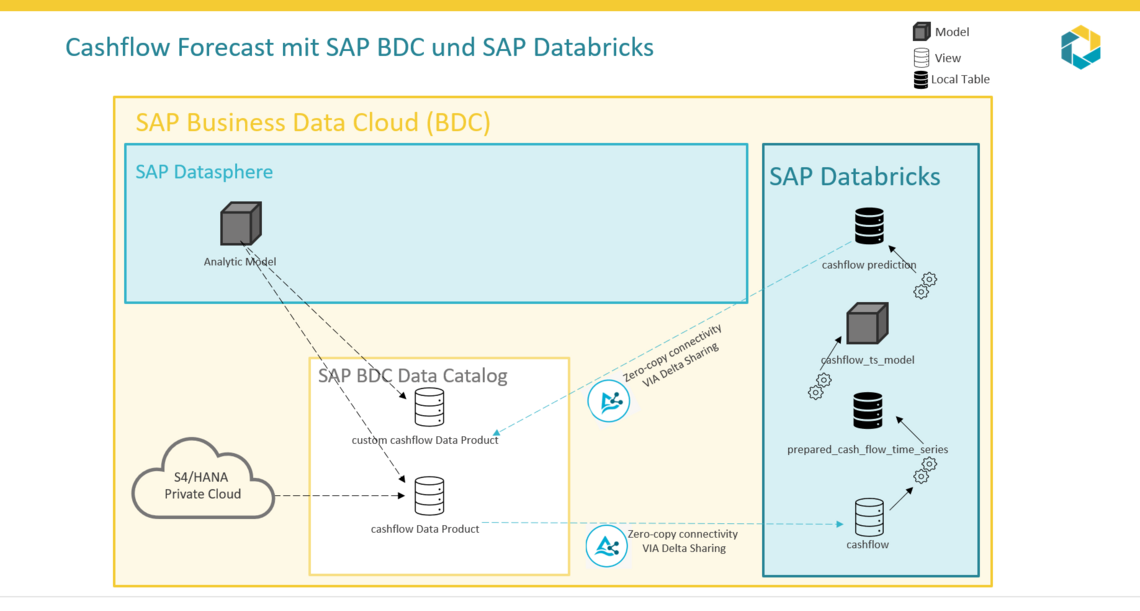
Nachdem wir im ersten Schritt den sicheren Zugang zu den S/4HANA-Daten in unserer Databricks-Umgebung hergestellt haben, widmet sich dieser Abschnitt der Datenanreicherung und Vorbereitung für unser Zeitreihen-Forecasting-Modell.
Ziel ist es, das Cash Flow-Datenprodukt so umzuformen, dass es für die Vorhersage des Cashflows in den kommenden Perioden optimal nutzbar ist. Das folgende Notebook demonstriert den gesamten Workflow, der später in die SAP Datasphere in der SAP Business Data Cloud (BDC) zurückgespielt wird.
Den vollständigen Code, der in diesem Video demonstriert wird, ist hier zufinden: Notebook
Demonstrations-Workflow umfasst die folgenden vier Hauptschritte:
1. Pakete installieren und importieren
Wichtig: Zur Isolierung der erstellten Daten-Assets erstellen wir einen Katalog (<CATALOG_NAME>, z.B. uc_cash_liquidity_forecast) und ein entsprechendes Schema (<SCHEMA_NAME>, z.B. grp041) im Databricks Unity Catalog.
2. Datenprodukt Cashflow laden
Aus dem BDC stellen wir eine Delta-Enabled lokale Tabelle über die Delta-Share bereit, die uns eine Tabelle mit mehreren Einträgen für denselben Primärschlüssel liefert.
Der Datensatz enthält die Spalte __OPERATION_TYPE, die die Transaktionsart (Insert, Update, Delete) kennzeichnet, sowie die Spalte __TIMESTAMP, die angibt, wann diese Änderung erfolgt ist.
Da wir die Cashflow-Transaktionssätze verwenden möchten, transformieren wir unseren Datensatz so, dass pro Primärschlüssel der aktuellste Eintrag geliefert wird.
Falls der aktuellste Eintrag eine Löschung darstellt, wird dieser Datensatz herausgefiltert.
3. Daten für Zeitreihen-Forecasting vorbereiten
Die Datenvorbereitung ist entscheidend für die Qualität der Prognose. Wir modellieren die Daten auf einer monatlichen Zeitreihe, basierend auf dem Buchungsdatum (Posting date), da dieses den Zeitpunkt der Cashflow-Buchung markiert.
Folgende Transformationsschritte werden durchgeführt:
-
Ersetzen leerer Strings durch Nullwerte.
-
Auswahl notwendiger Spalten und Filtern ungültiger Datumsangaben/Nullwerte im Buchungsdatum.
-
Abrunden des Buchungsdatums auf den Monat (floor) und Umbenennung der Datums- und Wertspalten.
-
Gruppierung der Daten nach Datum und Summierung des Cashflows pro Monat.
-
Erzeugung einer kontinuierlichen Zeitreihe zwischen dem minimalen und maximalen Datum der Daten.
-
Verknüpfung der generierten Zeitsequenz mit den Cashflow-Daten, um eine lückenlose Zeitreihen-Datenstruktur zu erhalten.
-
Auffüllen von Nullwerten mit 0 (da an diesen Tagen kein Cashflow erfasst wurde).
-
Konvertierung des Spark Dataframes in einen Pandas Dataframe für die ML-Modellierung.
4. Vorbereitete Zeitreihendaten speichern
Um sicherzustellen, dass für das Training und die spätere Prediction exakt dieselben vorbereiteten Daten verwendet werden, speichern wir den transformierten Daten im Databricks Feature Store. Dies eliminiert die Notwendigkeit, das Datenvorbereitungsskript in beiden Notebooks zu wiederholen.
Nach erfolgreicher Ausführung ist die erstellte Tabelle prepared_cash_flow_time_series im Unity Catalog unter dem entsprechenden Schema Ihres Benutzers abrufbar.